Trusted Data Infrastructure for Agentic AI
LifeGraph secures agentic workflows by structuring enterprise data into Smart Data Objects within a Knowledge Graph and enabling GraphRAG for context retrieval. By embedding identity, permissions, and provenance directly into the graph, every traversal enforces access control so agents only retrieve validated, authorized context. The result is a verifiable trust layer where every AI decision is grounded in governed, explainable data.

Trusted Data Infrastructure for Agentic AI
LifeGraph secures agentic workflows by structuring enterprise data into Smart Data Objects within a Knowledge Graph and enabling GraphRAG for context retrieval. By embedding identity, permissions, and provenance directly into the graph, every traversal enforces access control so agents only retrieve validated, authorized context. The result is a verifiable trust layer where every AI decision is grounded in governed, explainable data.
Trusted Data Infrastructure for Agentic AI
LifeGraph secures agentic workflows by structuring enterprise data into Smart Data Objects within a Knowledge Graph and enabling GraphRAG for context retrieval. By embedding identity, permissions, and provenance directly into the graph, every traversal enforces access control so agents only retrieve validated, authorized context. The result is a verifiable trust layer where every AI decision is grounded in governed, explainable data.
Where LifeGraph Fits:

Where LifeGraph Fits:
Where
LifeGraph Fits:

LifeGraph Features:

Smart Data Objects (SDOs) are data-native entities unique to LifeGraph that embed identity, permissions, metadata, relationships, and audit history directly into the data itself. This allows governance, consent, and lineage to be enforced in real time, ensuring data remains secure, portable, and verifiable across systems and AI workflows.

A Knowledge Graph is a graph-structured database that models real-world entities as nodes and their relationships as edges forming a network of interconnected facts. Data is stored and governed by an ontology that enables schema enforcement and logical inference. Unlike relational databases, Knowledge Graphs are optimized for relationship traversal and semantic reasoning across heterogeneous data types.
GraphRAG extends RAG by retrieving context through graph traversal, leveraging relationships between data points rather than flat document similarity. This allows AI systems to perform multi-hop reasoning, returning more precise, explainable answers grounded in connected data. The result is higher accuracy and deeper context, particularly for complex, relationship-driven queries.
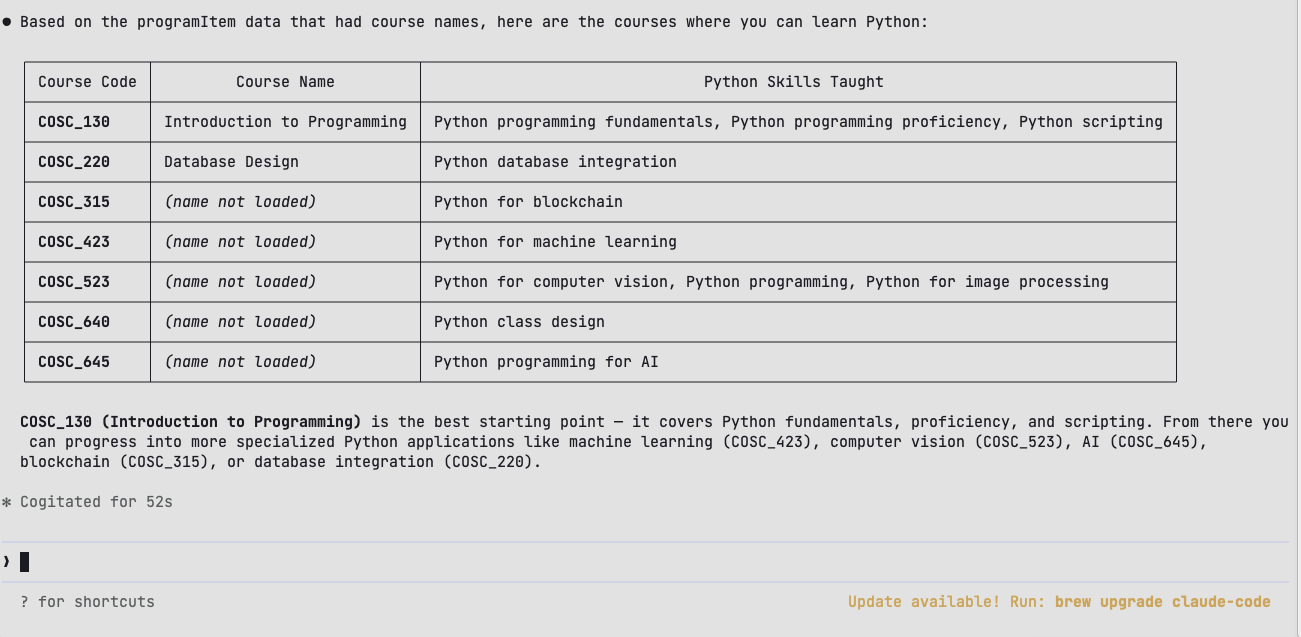
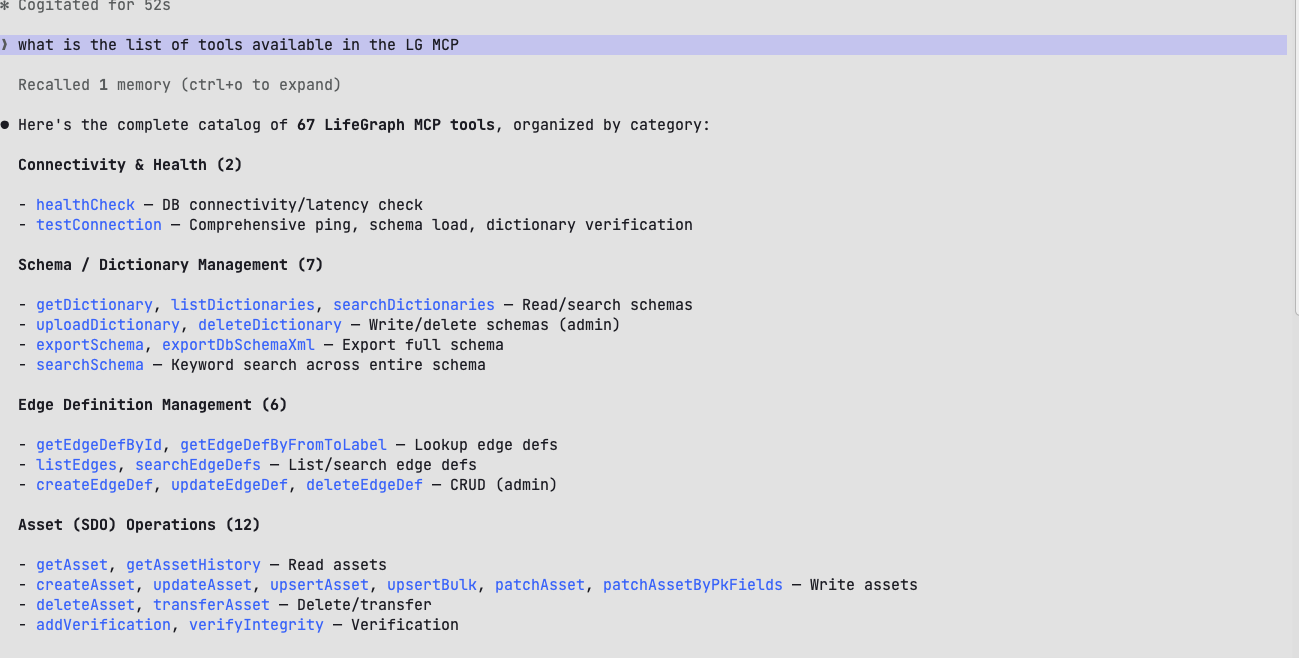
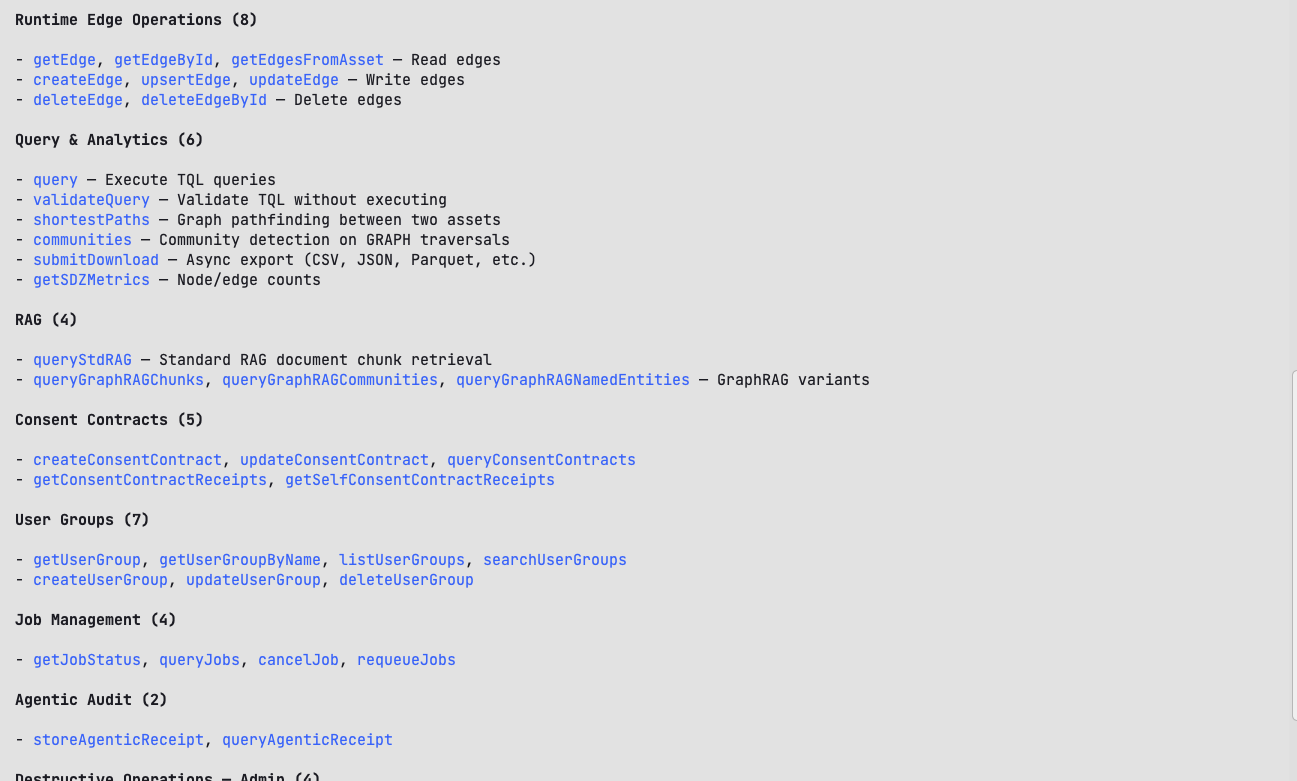
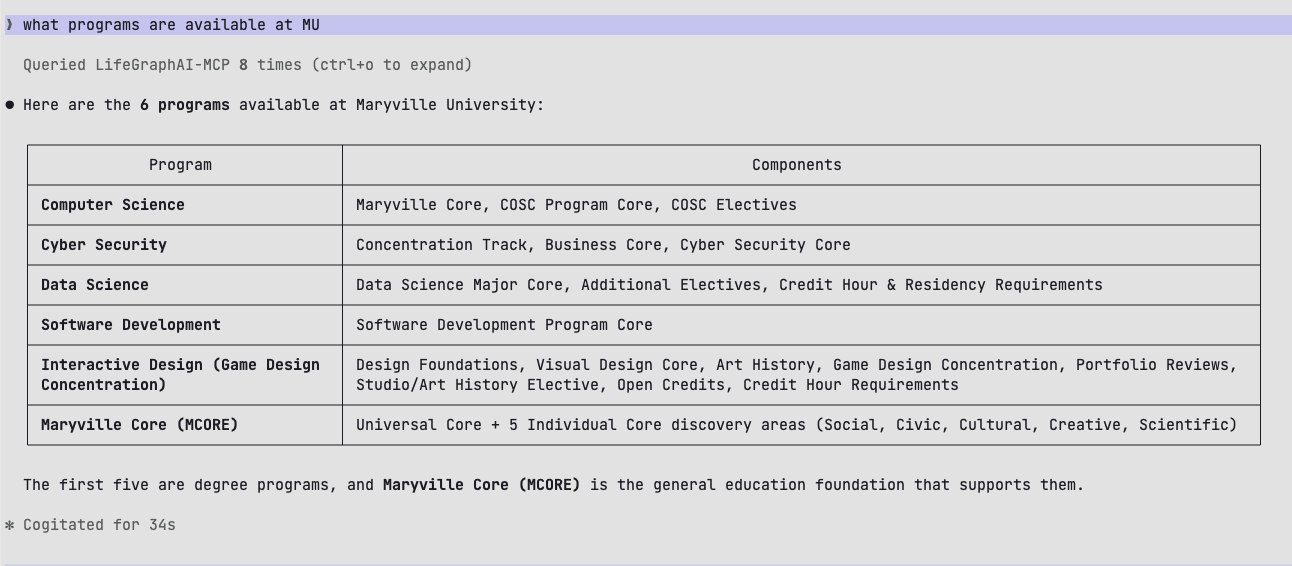

Consent Contracts are blockchain-backed smart contracts that embed consent rules and data provenance directly alongside data assets, ensuring that only authorized parties can access or process that data. They operate on an on-access basis, meaning the contract is triggered at the point of access to grant or restrict viewing permissions to assets beyond the original owner. This gives developers a programmable, auditable access control layer built directly into the data layer, eliminating the need to manage permissions as a separate system.

LifeGraph’s Job Manager is a core PaaS capability within the IQ data layer that handles asynchronous bulk data operations, decoupling large file uploads from the response cycle. Developers submit bulk flat files (CSV, XLS, XLSX, JSON, EDI, XML) via REST to the platform, which immediately returns a job ID used to independently poll and track the status of that operation. It sits alongside bulk ingest, data mapping, and transforms as part of the platform’s foundational data pipeline infrastructure.

Schema Management uses an admin-defined “dictionary” system within the data layer, allowing developers to define data structures anywhere from loosely structured to fully structured and typed schemas with required fields, datatypes, and rules for handling undefined attributes. This flexibility lets teams normalize heterogeneous data across integrations without rigid upfront modeling, while staying within the platform’s built-in governance and compliance guardrails.
")
LifeGraph Features:
Smart Data Objects (SDOs) are data-native entities unique to LifeGraph that embed identity, permissions, metadata, relationships, and audit history directly into the data itself. This allows governance, consent, and lineage to be enforced in real time, ensuring data remains secure, portable, and verifiable across systems and AI workflows.
A Knowledge Graph is a graph-structured database that models real-world entities as nodes and their relationships as edges forming a network of interconnected facts. Data is stored and governed by an ontology that enables schema enforcement and logical inference. Unlike relational databases, Knowledge Graphs are optimized for relationship traversal and semantic reasoning across heterogeneous data types.
GraphRAG extends RAG by retrieving context through graph traversal, leveraging relationships between data points rather than flat document similarity. This allows AI systems to perform multi-hop reasoning, returning more precise, explainable answers grounded in connected data. The result is higher accuracy and deeper context, particularly for complex, relationship-driven queries.
MCP (Model Context Protocol) is an open standard by Anthropic that defines a universal interface for connecting AI models to external tools, data sources, and services, eliminating the need for one-off custom integrations. It follows a client-server architecture where a host application connects to MCP servers that expose callable tools, resources, and prompts the model can invoke at runtime. Think of it as a standardized API layer that decouples your AI from its integrations, making your stack modular, extensible, and straightforward to build on.
Consent Contracts are blockchain-backed smart contracts that embed consent rules and data provenance directly alongside data assets, ensuring that only authorized parties can access or process that data. They operate on an on-access basis, meaning the contract is triggered at the point of access to grant or restrict viewing permissions to assets beyond the original owner. This gives developers a programmable, auditable access control layer built directly into the data layer, eliminating the need to manage permissions as a separate system.
LifeGraph’s Job Manager is a core PaaS capability within the IQ data layer that handles asynchronous bulk data operations, decoupling large file uploads from the response cycle. Developers submit bulk flat files (CSV, XLS, XLSX, JSON, EDI, XML) via REST to the platform, which immediately returns a job ID used to independently poll and track the status of that operation. It sits alongside bulk ingest, data mapping, and transforms as part of the platform’s foundational data pipeline infrastructure.
Schema Management uses an admin-defined “dictionary” system within the data layer, allowing developers to define data structures anywhere from loosely structured to fully structured and typed schemas with required fields, datatypes, and rules for handling undefined attributes. This flexibility lets teams normalize heterogeneous data across integrations without rigid upfront modeling, while staying within the platform’s built-in governance and compliance guardrails.
Since extra data can be stored directly embedded in the SDO (regardless of the dictionary) the data producer can set linear and source information next to the data without compromising or altering the actual data structure itself. This metadata can be used with TQL, jobs, consent contracts and other functions within the platform as a first-level information.
LifeGraph Features:
Smart Data Objects (SDOs) are data-native entities unique to LifeGraph that embed identity, permissions, metadata, relationships, and audit history directly into the data itself. This allows governance, consent, and lineage to be enforced in real time, ensuring data remains secure, portable, and verifiable across systems and AI workflows.
A Knowledge Graph is a graph-structured database that models real-world entities as nodes and their relationships as edges forming a network of interconnected facts. Data is stored and governed by an ontology that enables schema enforcement and logical inference. Unlike relational databases, Knowledge Graphs are optimized for relationship traversal and semantic reasoning across heterogeneous data types.
GraphRAG extends RAG by retrieving context through graph traversal, leveraging relationships between data points rather than flat document similarity. This allows AI systems to perform multi-hop reasoning, returning more precise, explainable answers grounded in connected data. The result is higher accuracy and deeper context, particularly for complex, relationship-driven queries.
MCP (Model Context Protocol) is an open standard by Anthropic that defines a universal interface for connecting AI models to external tools, data sources, and services, eliminating the need for one-off custom integrations. It follows a client-server architecture where a host application connects to MCP servers that expose callable tools, resources, and prompts the model can invoke at runtime. Think of it as a standardized API layer that decouples your AI from its integrations, making your stack modular, extensible, and straightforward to build on.
Consent Contracts are blockchain-backed smart contracts that embed consent rules and data provenance directly alongside data assets, ensuring that only authorized parties can access or process that data. They operate on an on-access basis, meaning the contract is triggered at the point of access to grant or restrict viewing permissions to assets beyond the original owner. This gives developers a programmable, auditable access control layer built directly into the data layer, eliminating the need to manage permissions as a separate system.
LifeGraph’s Job Manager is a core PaaS capability within the IQ data layer that handles asynchronous bulk data operations, decoupling large file uploads from the response cycle. Developers submit bulk flat files (CSV, XLS, XLSX, JSON, EDI, XML) via REST to the platform, which immediately returns a job ID used to independently poll and track the status of that operation. It sits alongside bulk ingest, data mapping, and transforms as part of the platform’s foundational data pipeline infrastructure.
Schema Management uses an admin-defined “dictionary” system within the data layer, allowing developers to define data structures anywhere from loosely structured to fully structured and typed schemas with required fields, datatypes, and rules for handling undefined attributes. This flexibility lets teams normalize heterogeneous data across integrations without rigid upfront modeling, while staying within the platform’s built-in governance and compliance guardrails.
Since extra data can be stored directly embedded in the SDO (regardless of the dictionary) the data producer can set linear and source information next to the data without compromising or altering the actual data structure itself. This metadata can be used with TQL, jobs, consent contracts and other functions within the platform as a first-level information.
How LifeGraph Compares:

How LifeGraph Compares:
How LifeGraph Compares:

LifeGraph is available through our trusted partners, and directly from us.



LifeGraph is available through our trusted partners, and directly from us.
LifeGraph is available through our trusted partners, and directly
from us.
